
In this blog, we will dive into the essential concepts of full fine-tuning and LoRA fine-tuning, two popular techniques in the model adaptation space. I’ll break down what model fine-tuning really means, why we use it, and how LoRA enables efficient fine-tuning by reducing the parameters we need to train. You’ll also learn about the core ideas behind LoRA’s low-rank approximation and how it saves time, memory, and computational resources. Whether you’re into deep learning or just curious about AI optimizations, this video will provide valuable insights into tuning large models effectively.
For detailed information, please watch the YouTube video: Fully Fine-Tuning vs. LoRA in LLM: Simple Explained
In the field of model fine-tuning, terms like “full fine-tuning” and “LoRA fine-tuning” are frequently heard. In this video, I’ll explain the difference between these two approaches.
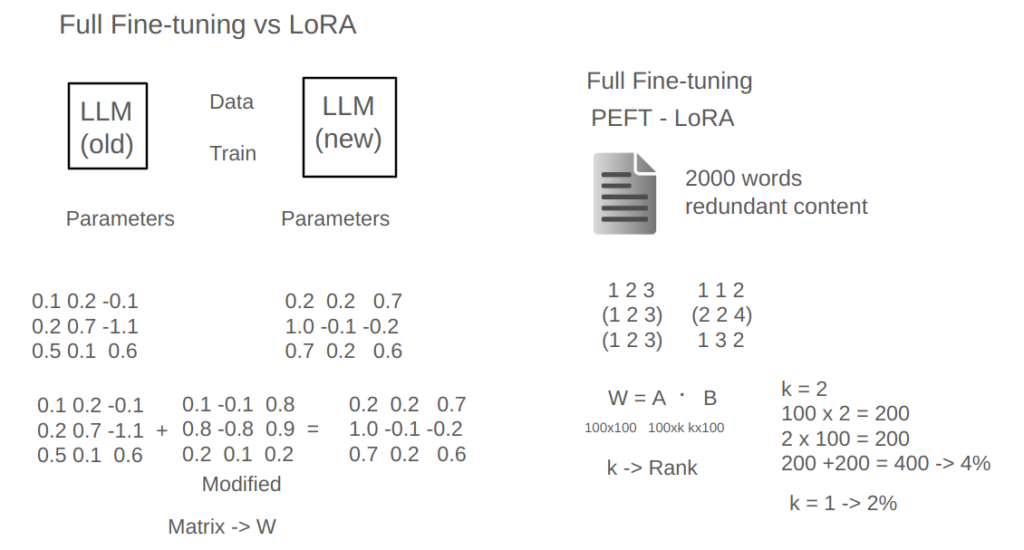
First, we need to understand what model fine-tuning is. Essentially, model fine-tuning is used when we find that a model is lacking in a certain aspect. Through training techniques, we update the model to improve its capability in that area. Fine-tuning fundamentally alters the model by adjusting its parameters, which essentially means changing from the original parameters to new ones. Since a large model might have billions, even hundreds of billions of parameters, these parameters represent an enormous collection of numbers, which are often organized in rows and columns.
For example, a small model might have a 3×3 grid of parameters, totaling nine numbers, but a large model can easily have hundreds of billions of parameters. For demonstration, let’s consider a simplified example. After fine-tuning, some of these numbers will change. Training essentially transforms these parameters from their initial state to a new one. For instance, a parameter value of 0.1 might change to 0.2, and so on. We can view this change as an adjustment, adding or subtracting a small value to achieve the fine-tuned model.
Now, a straightforward way to fine-tune is to learn each parameter individually. This is called “full fine-tuning,” where, if our model originally has ten billion parameters, we adjust each of these individually, which is resource-intensive. But what if we could use fewer resources for fine-tuning? This approach, known as Parameter-Efficient Fine-Tuning (PEFT), is where LoRA comes in.
To understand LoRA, let’s start with an analogy. Imagine we ask someone to write a 2,000-word article. If that person tends to be verbose, they might fill it with repetitive or redundant content, even if the core ideas only need a couple of hundred words. Similarly, large models with billions of parameters may contain redundant information. LoRA leverages this redundancy, assuming that while the model has many parameters, the information they hold may be limited and can be represented with fewer resources.
In LoRA fine-tuning, instead of modifying every parameter, we assume that the parameters can be organized in a way that allows us to capture the needed information with fewer adjustments. Using linear algebra, we represent the large matrix of parameters (W) as the product of two smaller matrices, A and B. Instead of learning the full matrix W with ten thousand parameters, we now only need to learn A and B, which have far fewer parameters—perhaps 400 instead of 10,000. The values of A and B capture the essential characteristics of W, allowing us to approximate it with far fewer resources.
The smaller number of parameters in A and B reduces the resources needed for learning, both in terms of memory and computational cost. This process makes LoRA highly efficient because we only need to adjust a fraction of the parameters, often just a few percent of the original.
In summary, full fine-tuning requires learning each parameter individually, while LoRA replaces this process by training two smaller matrices to approximate the original, significantly reducing resource usage. This technique helps save memory and computing power, making LoRA an effective solution for fine-tuning large models.



