In this blog, we will explore the step-by-step process of RAG (Retrieval-Augmented Generation), a powerful method to enhance large language models with custom knowledge bases. This video breaks down how RAG allows us to incorporate enterprise knowledge and private databases, transforming text into vectorized chunks stored in a vector database. Learn how user queries are converted into vectors, retrieved as relevant context, and used to generate precise responses. Perfect for anyone interested in deploying advanced AI systems that leverage unique data to deliver accurate answers.
For detailed information, please watch the YouTube video: Understanding the RAG Workflow: Simple Explained
For the implementation of large language models (LLMs), one of the most commonly used methodologies today is RAG (Retrieval-Augmented Generation). Through RAG, we can integrate enterprise knowledge or private knowledge bases with large models to address user queries effectively.
Here’s an overview of the RAG process:
Core Concept of RAG
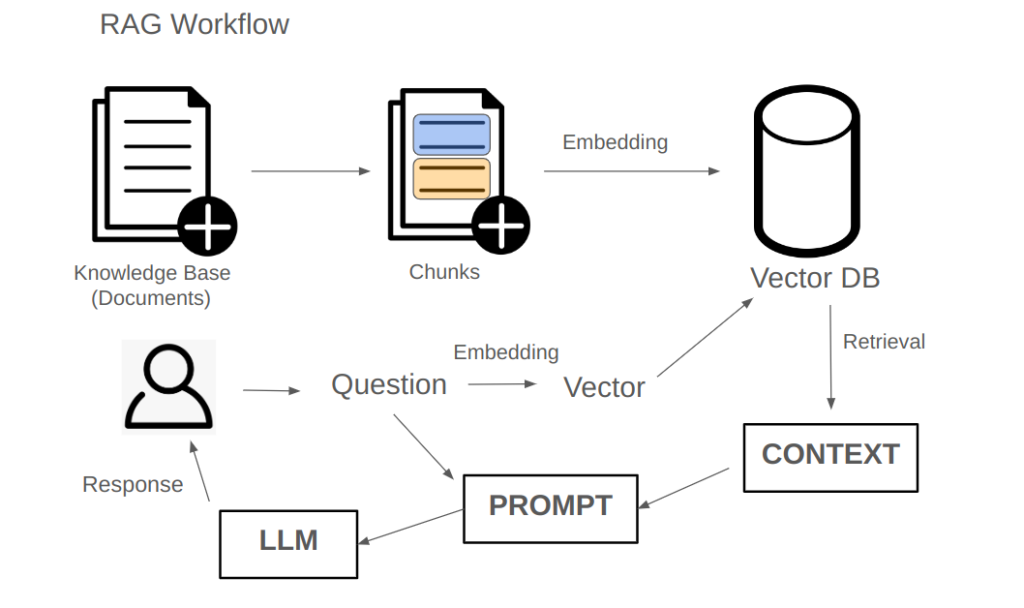
At the heart of RAG lies the knowledge base. First, we need a collection of text, which forms the foundation of our knowledge base. This knowledge base consists of a vast amount of textual data.
Storing Text in a Vector Database
The next step is to store this text in a database. Here, we use a vector database, a modern database system designed to facilitate retrieval operations efficiently. Once the text is stored, we can retrieve other texts from this database that are similar to a given query.
To optimize the retrieval process, the data must first be preprocessed before being stored in the vector database:
- Splitting Text into Paragraphs (Chunks)
Large documents are divided into smaller segments or paragraphs. Each paragraph becomes a standalone unit. Various methods can be used to perform this segmentation, though we won’t go into the specifics here. By the end of this step, we have a set of segmented paragraphs or chunks. - Embedding Paragraphs
Before storing these segments in the vector database, we convert each one into an embedded vector format, a process called embedding. These embeddings represent the textual information in a numerical vector form. Once this transformation is complete, the knowledge is now effectively stored in the vector database.
Retrieving Information
Now, when a user poses a question, how do we respond? This involves the following steps:
- Converting the User Query into a Vector
The user’s question must also be converted into a vector. This requires an embedding tool to transform the query into a numerical representation. - Retrieving Relevant Paragraphs
Using the query vector, we search the vector database to retrieve paragraphs that are likely to contain the answer. The database returns the top results, such as the 10 most relevant paragraphs. This step is referred to as retrieval, and the retrieved results are collectively called the context. The context provides potential clues or answers to the user’s question.
Constructing the Prompt
The next step is to combine the user’s query with the retrieved context into a prompt. This prompt is structured in such a way that the large model can generate an answer based on the context.
Finally, the prompt is fed to the large model, which processes it and generates a response. This response is then returned to the user.
Key Takeaway
The most critical part of the RAG workflow is ensuring the documents are appropriately segmented and stored in the vector database. A well-structured knowledge base and efficient retrieval process form the backbone of the RAG methodology, enabling large models to deliver accurate and context-aware answers.



