
In this blog, we will explain the role of vector databases and why they are essential for efficient text vector retrieval in RAG workflows. We’ll look at how vector comparisons work, the importance of similarity measures like cosine similarity, and the challenges of handling large numbers of high-dimensional vectors. I’ll break down how vector databases tackle the complexities of scaling and speeding up retrieval, making AI applications faster and more responsive. Perfect for those interested in the technical side of vector search and optimizing retrieval in large-scale AI systems!
For detailed information, please watch the YouTube video: Understanding Why Vector Databases Are Essential for RAG
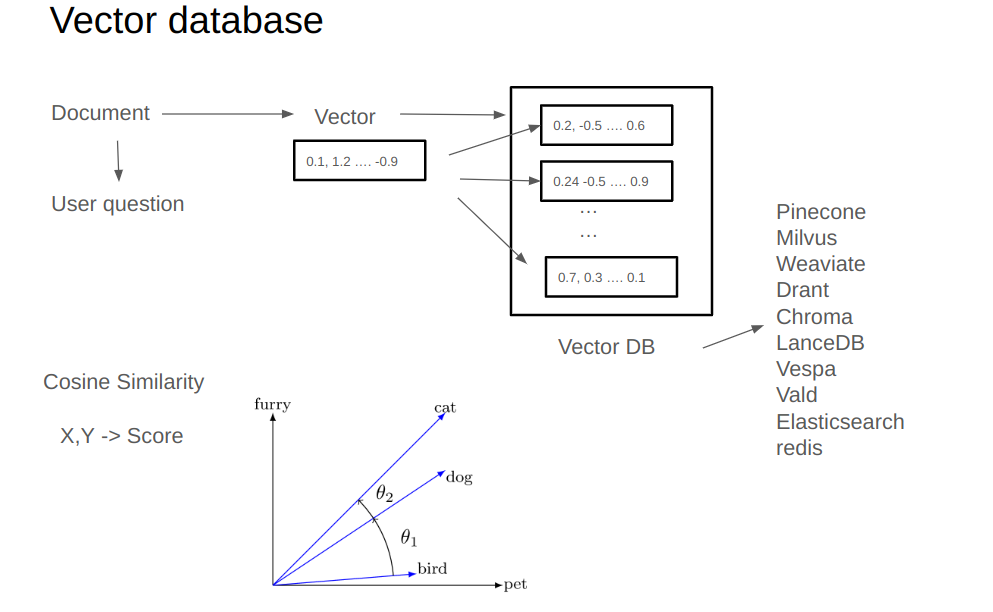
In the classic RAG workflow, a critical step is to take a given text, convert it into a vector, and then search within a vector database for other vectors that are similar to it. Suppose we have a vector database filled with numerous vectors; the task is to match the input vector with those stored in the database. The core idea is to search the database to identify which vector is most similar to the input vector.
The Similarity Search Process
The matching process involves comparing the input vector with each stored vector to calculate their similarity. This comparison is repeated for every vector in the database. For example:
- Compare the input vector with the first stored vector to calculate a similarity score.
- Compare it with the second vector to compute another similarity score.
- Continue this process for all vectors in the database.
Once all the similarity scores are calculated, the system selects the top results, such as the 10 or 20 most similar vectors, and returns them to the user. This comparison process is computationally intensive, with a time complexity of O(N), where N is the total number of vectors in the database.
Calculating Vector Similarity
To compute the similarity between two vectors, the most commonly used method is cosine similarity. This method determines how similar two vectors are by calculating the angle between them in a vector space. For example:
- Given two vectors, X and Y, cosine similarity outputs a similarity score.
- The smaller the angle between the vectors, the higher their similarity.
If we visualize three vectors in a space:
- A smaller angle between two vectors indicates higher similarity.
- Conversely, a larger angle means lower similarity.
This is the fundamental principle of cosine similarity. The time complexity for calculating cosine similarity between two vectors is O(d), where d is the dimensionality of the vectors.
Combined Complexity of Similarity Search
When a user submits a query, which is represented as a vector, the overall time complexity for retrieving relevant results is O(N) × O(D):
- O(N) accounts for the number of vectors in the database.
- O(d) accounts for the dimensionality of each vector.
As the database grows (i.e., N becomes large) or as the vector dimensions increase (i.e., D becomes large), the complexity grows significantly. This makes the system slower, which is undesirable in practical scenarios where users expect quick responses.
The Need for a Vector Database
A vector database is specifically designed to address these challenges by enabling fast vector retrieval. It achieves this by optimizing the complexity of the similarity search process. Essentially, a vector database:
- Reduces the time complexity associated with searching a large number of vectors (N).
- Optimizes the computation required for high-dimensional vectors (D).
Modern Vector Database Solutions
Modern vector databases incorporate advanced techniques to lower the computational complexity. They focus on enabling efficient retrieval and fast responses, even when handling large-scale datasets or high-dimensional vectors. These optimizations are essential to meet the performance demands of real-world applications and are a key consideration in the design of modern vector databases.



