
In this blog, we will break down common practical challenges encountered when building applications with Retrieval-Augmented Generation (RAG) workflows. While RAG can streamline large-model applications, real-world implementation requires careful handling of document types, chunking, embedding, retrieval accuracy, and more. From selecting vector databases to fine-tuning prompts and managing response quality, I walk through the key engineering and design details that make RAG workflows truly effective. Perfect for anyone navigating the complexities of RAG-based AI solutions and looking to optimize their approach!
For detailed information, please watch the YouTube video: RAG Practical Challenges
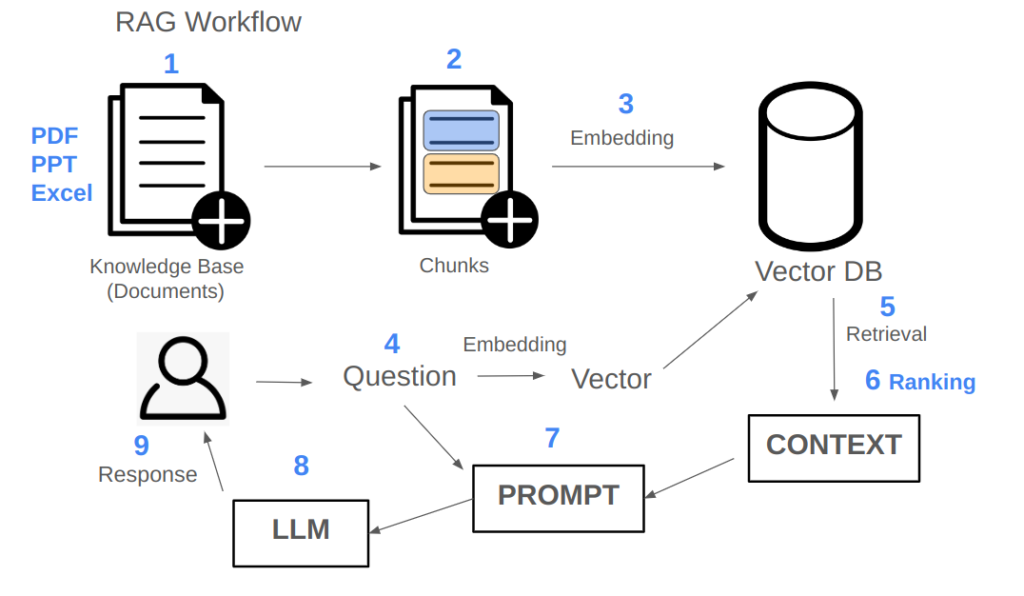
Although we can quickly build large-model applications based on the classic RAG (Retrieval-Augmented Generation) workflow, there are many details we need to consider. If these details are not handled well, the final performance may fall short of our expectations.
First, let’s discuss document handling. There are numerous types of documents to process, such as PDFs, PPTs, and Excel files. Each document type may have different formats, making the reading and processing stage quite challenging. This is one of the main difficulties commonly encountered.
The second issue is segmenting documents into meaningful chunks after reading. This brings us to the third challenge: embedding these chunks. Various embedding techniques are available, and choosing the right vector database for these chunk embeddings is a critical engineering decision.
Next, after obtaining a query, we generate an embedding for it. However, a challenge here is that the question may need further processing. For instance, the query might be short or lack sufficient context, necessitating expansion or rewriting.
Once we have a processed query, we need an effective retrieval process to obtain relevant context. If we don’t retrieve suitable context, the entire downstream process fails. Thus, retrieval efficiency and accuracy are crucial, often relying on traditional search engine techniques. After retrieval, we may receive some context, but it might contain irrelevant or excessive information. If we overload the prompt with too much data, it can hinder performance.
In many cases, we add an extra step after retrieval called ranking. Retrieval can be seen as a coarse filtering (or recall), while ranking refines the results. After ranking, we add the refined context to the prompt.
The next question is how to design the prompt. A well-crafted prompt can better tap into the model’s potential, so prompt design is crucial. Once we have a prompt, we call the large model. Here, the choice of model is significant: should we use a general-purpose model, an open-source one, or a fine-tuned model tailored to our needs? Fine-tuning may require substantial resources.
After obtaining the model’s response, we decide whether to return it to the user directly or process it further. Some responses may fail to meet requirements or even violate certain guidelines, so we usually include a quality check. If the response doesn’t pass this check, it loops back into the workflow for adjustments.
These steps are all part of the detailed work required for implementing RAG-based solutions. Depending on the project, our focus may shift: some projects may require attention to data processing and chunking, while others may emphasize retrieval and ranking algorithms.



