
In this blog, we will guide you through the practical steps of choosing between prompt engineering, RAG (Retrieval-Augmented Generation), and fine-tuning when working with large language models. Using clear examples, we’ll show how each approach can address specific challenges: refining input with prompt engineering, adding context with RAG, or enhancing model capabilities through fine-tuning. This structured approach helps you solve problems efficiently, without unnecessary complexity. Perfect for those new to AI applications or anyone looking to optimize their model workflows!
For detailed information, please watch the YouTube video: Prompt Engineering vs. RAG vs. Fine-Tuning: How to Choose? A Practical Guide for Everyone
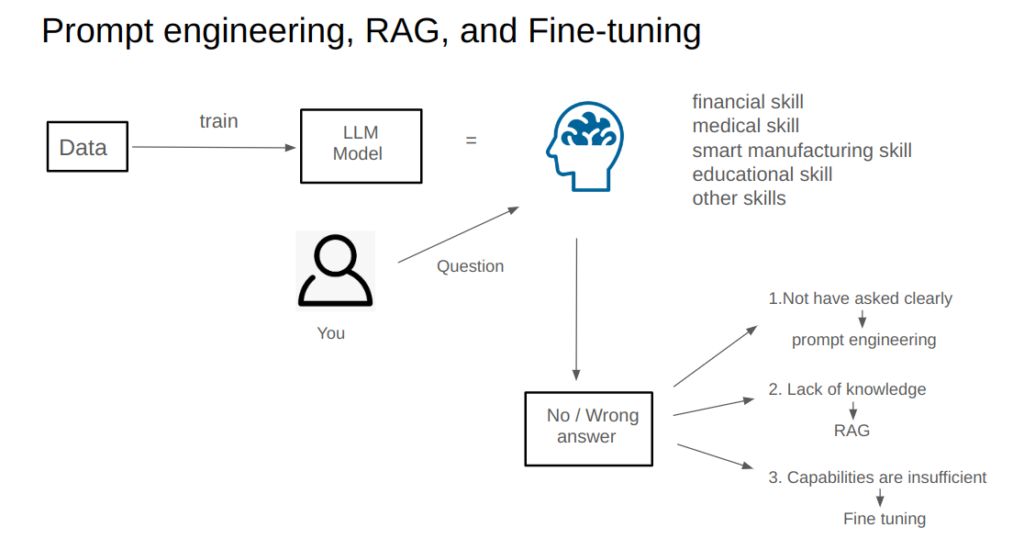
When tackling engineering challenges with large language models (LLMs), how do we decide between prompt engineering, retrieval-augmented generation (RAG), and fine-tuning? In this post, I’ll break it down step by step, using a practical analogy to make the differences crystal clear.
Understanding the Foundation of Large Models
Large models are trained on massive and diverse datasets, covering fields such as finance, healthcare, manufacturing, and education. This diversity gives these models a wide range of capabilities, much like a highly skilled and knowledgeable person.
Let’s imagine the large model as an intelligent brain, like a person (say, me) with expertise across multiple areas—AI, fintech, medicine, management, and more. However, just like any individual, even this “brain” might not always provide the answer you need. When this happens, the solution often lies in one of three approaches: prompt engineering, RAG, or fine-tuning.
The Analogy: Why Didn’t I Answer Your Question Correctly?
Imagine you come to me with a question, but my response isn’t what you were looking for. Why not? Let’s analyze the potential reasons and corresponding solutions.
1. The Question Isn’t Clear: Prompt Engineering
If your question is unclear or lacks detail, I may not understand what you truly want. The solution? Rephrase or structure your question more effectively, providing specifics or context to make your request clear.
This process is akin to prompt engineering—crafting precise and detailed inputs to help the model generate better responses.
- Example: If you ask, “How does AI work in finance?” a vague prompt may lead to a generic answer. By specifying, “Explain the use of predictive modeling in credit risk analysis,” you can get a more tailored response.
If this resolves the issue, great! If not, we move to the next step.
2. Lack of Context: Retrieval-Augmented Generation (RAG)
Perhaps your question falls into a domain where I lack sufficient knowledge. For example, while I know a lot about AI, I might not be an expert in AI for architecture. In this case, you could provide me with contextual information—background knowledge about architecture relevant to your question. This additional context enables me to give a more informed answer.
This corresponds to RAG, where we augment the model’s capabilities by supplying external knowledge or context at query time.
- Example: You ask, “How can AI optimize building designs?” By attaching relevant documents, blueprints, or case studies to your query, you enable the model to respond more effectively.
If this still doesn’t resolve the problem, it’s time to consider the third possibility.
3. Abilities Are Insufficient: Fine-Tuning
Sometimes, the issue lies in my core capabilities. Even with detailed context, I might not have the intrinsic skills to address your question effectively. To improve, I would need to enhance my expertise—in other words, learn and train further.
This is analogous to fine-tuning, where the model itself is updated to better handle specific tasks or domains. Unlike prompt engineering and RAG, which operate externally, fine-tuning involves modifying the large model itself.
- Example: If you frequently need architectural insights, fine-tuning the model on a specialized dataset of architectural knowledge can make it inherently better at answering such queries.
The Engineering Workflow: Start Simple, Go Deeper if Needed
In engineering, the process should follow a clear sequence:
- Start with Prompt Engineering: Refine your inputs to see if the model can solve the problem with better instructions.
- Move to RAG: If prompt engineering isn’t enough, supply additional context or external knowledge to augment the model’s response.
- Consider Fine-Tuning: Only as a last resort, if the model’s core capabilities are insufficient, proceed to fine-tuning.
Why Not Start with Fine-Tuning?
Fine-tuning can be resource-intensive, requiring significant time, cost, and expertise. By starting with simpler methods like prompt engineering and RAG, you can often achieve your goals without modifying the model itself. Fine-tuning should be reserved for scenarios where the problem is domain-specific, and no external adjustments suffice.
Key Takeaways
- Prompt engineering is about asking better questions to leverage the model’s existing capabilities.
- RAG involves providing the model with external knowledge to fill gaps in its understanding.
- Fine-tuning enhances the model itself, making it better suited for specific tasks but at a higher cost and complexity.
By following this structured approach, you can maximize efficiency and effectiveness in engineering applications.



