
In this blog, we will break down the complete two-stage process of training LLM, making it easy to understand. Starting with general pre-training using vast amounts of data, I explain how we build a foundational model and then improve it with fine-tuning techniques like SFT (Supervised Fine-Tuning) and alignment. Learn how fine-tuning works, how we use user feedback in alignment, and why methods like PPO and DPO are essential. If you’re looking for a clear, accessible explanation of large model training, this video is for you!
For detailed information, please watch the YouTube video: LLM Pre-Training and Fine-Tuning: Simple Explained
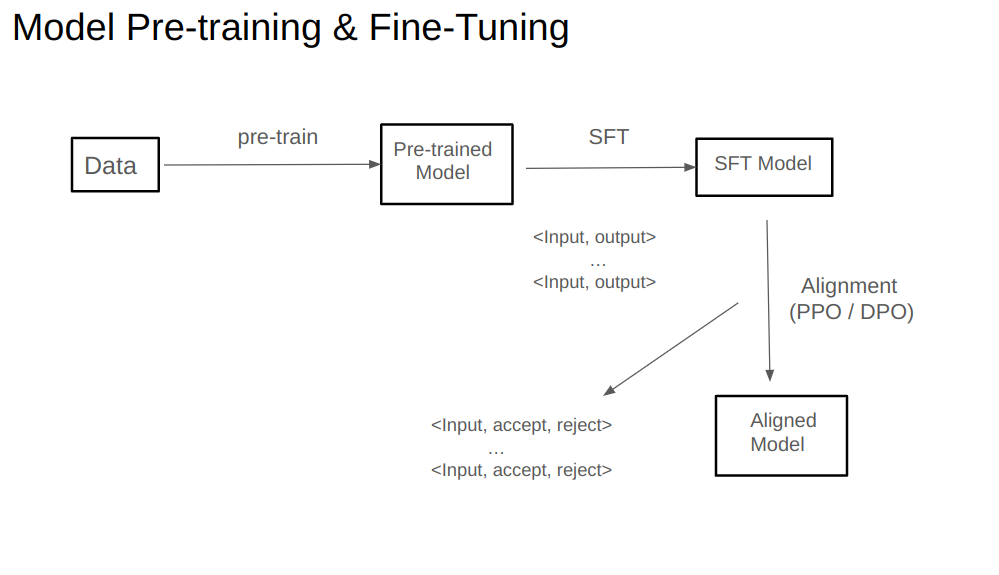
How should we approach the training of large models? Generally, this process is divided into two main stages. The first stage is pre-training the model, where we train a large model using massive amounts of data. This type of model is what we call a general-purpose model. However, there may be some capabilities that this general-purpose model lacks. In such cases, we need to improve the model using specialized or proprietary data, a process known as fine-tuning.
Model fine-tuning itself has two key stages. The first stage is SFT, or Supervised Fine-Tuning, and the second stage is the alignment phase. The data used here is often vast amounts of text, which can come from the internet, books, and other sources. Through this pre-training process, we obtain a pre-trained model. This pre-training stage gives us a generic large model, but it may still lack some capabilities required for specific scenarios. Therefore, we often perform further training on open-source models, which we refer to as fine-tuning.
The first step in fine-tuning is usually SFT. During the SFT phase, we need instruction fine-tuning data, which is structured with two fields. The first field is the input, representing the user’s question, and the second field is the output, which is the standard answer. This standard answer is usually annotated by human users; for example, we might pose a question and invite experts to provide standardized responses. Using thousands, tens of thousands, or even hundreds of these instructional samples, we conduct SFT training to obtain an SFT model.
The SFT model learns the type of answer we want for each question. However, it hasn’t learned what we don’t want. After deploying the SFT model, we can collect real feedback data from users, such as likes and dislikes. A like suggests a good output, while a dislike indicates the answer may need improvement. This is where the alignment phase comes in. The model obtained from alignment is called an aligned model.
For alignment, we need a new dataset with a different structure from SFT data. For the same input, we have two different outputs: one labeled as “accept” and the other as “reject.” This type of data is essential for the alignment phase. In SFT, we only tell the model what we want, teaching it to imitate good responses. During alignment, we also show it what we don’t want.
Gathering alignment data is relatively easier since, once the system is live, we can run A/B tests and let users help us label data. Even if users don’t explicitly label the data, we can infer this from logs.
To summarize, pre-training builds a general-purpose model with a wide range of abilities. Yet, this model may not fully meet our specific needs, so we conduct SFT to enhance or amplify certain capabilities, resulting in an SFT model. However, the SFT model may still have flaws, such as not following instructions strictly, repeating responses, or answering questions it shouldn’t. As we observe more of these issues post-deployment, we gather alignment data to teach the model what not to do and conduct further training. This gives us a refined model that can be deployed.
In the alignment process, we commonly use methods such as PPO or DPO. PPO relies on reinforcement learning and is quite challenging to train, while DPO is more straightforward and has recently become a popular choice in alignment tasks.



